I took a recent foray into a new programming language, Kotlin. It was not planned but not surprising either. For a while I have felt the itch to expand into different programming paradigms because, frankly, I am getting bored with Python. Python is still my go to at work when I want to get something done that can’t easily be done in Excel or SQL. But ever since I was a kid, I was fascinated with programming and always found myself experimenting with different languages and techniques. So professionally, the clock was always ticking on my need to venture out into something new. I remember one Christmas Eve, 2003 I think, we were waiting for my sister and brother in law to drive in from out of state and everyone was doing their own thing around the house in the meantime. My own thing was coding up a chatbot in Basic. No, I did not invent the Attention mechanism in 2003, but I did make a bot that could have a tiny, if predictable, conversation with you. I did it because it was fun and new.
My desire to expand out from Python has been some time coming. My first exploration was in the Mojo language which is a superset of Python that looks and performs more like typed languages. Mojo came out with this amazing intro video with incredible production value. That was in 2023 and we still don’t have a stable release. When we do, I’ll be there.
The next foray was towards the darling of the systems engineering world, Rust. It had a lot of what I was looking for which can be summed up as features that improve on Python and make it distinct. Rust was billed and still is a well loved language, especially by engineers closer to the metal of different systems, including the Linux Kernel itself. It is fast, memory safe, and modern in its design. I wanted my new language to have an established connection to machine learning in some form, or at least an up and coming ecosystem with dedicated people, whether behind a company or in the wilds of open source. Rust had a lot of momentum, but was not the ML powerhouse I was looking for. The nugget it did contain was Polars, which I still use, but through the Python api ;)
Scala stood out to me after Rust. One of the main languages behind spark. A tried and true titan of the data world. Scala looked differentiated enough and seemed exciting at first glance because of its expressiveness. However that buzz died when I realized that the community is dwindling and the language is basically not sure of itself going forward. There will probably always be systems running Scala around, but the trend is negative.
I finally stumbled on Kotlin. Another darling of the Java Virtual Machine (JVM) world mainly used for Android development. At first glance, you wouldn’t think this language was what I was looking for. One of my early exposures was through a post on Linkedin that I initially disagreed with claiming that Kotlin would be the the next Python killer. Well we’ve heard that story a billion times about SQL, why should another entrenched language like Python ever sound a retreat? I thought the idea of a Python killer was ridiculous. I still think that, just less so after playing with Kotlin. Something about the language grabbed me when I saw it. An aesthetic that I couldn’t put my finger on but I knew I liked. Maybe there was something there, so I decided to get hands on and experience it for myself. Building a program that helps me optimize my daily caffeine intake seems to be a good starting point given its simplicity and usefulness. Before we jump into the code, let’s do some basic diff eq. Don’t worry, this is the BASICs, nothing more.
The Math
To estimate the behavior of coffee in the body, we will use the notion of half life. The definition of half life in this context is the time it takes for half of the current concentration to be removed from the body. Coffee along with many other phenomenon like radioactive decay can be modeled by the following differential equation
\[dC = C*dt\]Rearranging and introducing a constant k (which helps model different half life values) we get
\[\frac{dC}{C} = k*dt\]Integrate both sides
\[ln(C) = kt + C_{cons}\]Solve for C (note that \(C_0\) is derived from \(C_{cons}\))
\[C_t = C_0exp(kt)\]Half life modeling is an example of what are called separable differential equations because they involve a tiny bit of algebra and are solved by direct integration. We now have our expression for the concentration of coffee (or any other substance with a half life) at a certain time, but we first need to derive k, whose value is different for different half lives. We know from medical research that the average value of the elimination half life in healthy adults is 5 hours. Using that information, we can solve for our k constant as follows.
\[0.5*C_0 = C_0*exp(k*5)\]which yields a k value of approximately -0.139. We have everything we need, let’s code it up in Kotlin!
The Kode
package org
import kotlin.math.
import java.time.LocalTime
import java.time.Duration
import org.jetbrains.kotlinx.dataframe.*
import org.jetbrains.kotlinx.dataframe.api.*
import org.jetbrains.kotlinx.dataframe.io.*
import org.jetbrains.kotlinx.kandy.dsl.plot
import org.jetbrains.kotlinx.kandy.letsplot.layers.line
import org.jetbrains.kotlinx.kandy.letsplot.settings.LineType
import org.jetbrains.kotlinx.kandy.letsplot.x
import org.jetbrains.kotlinx.kandy.letsplot.y
import org.jetbrains.kotlinx.kandy.letsplot.export.save
import org.jetbrains.kotlinx.kandy.letsplot.feature.layout
import org.jetbrains.kotlinx.kandy.util.color.Color
data class Coffee(val time: LocalTime, var concentration: Double)
fun get_dc_times(start_time: LocalTime, end_time: LocalTime): List<Coffee> {
// Get time schedule
var run_time = start_time
var ret_list: MutableList<Coffee> = mutableListOf()
while (run_time <= end_time) {
ret_list.add(Coffee(run_time, 0.0))
run_time = run_time.plusMinutes(30)
}
return ret_list
}
fun calculate_conc(dat_list: List<Coffee>, sc: Double, st: LocalTime, k: Double): List<Coffee> {
// Calculate cconcentration
for (coffee in data_list) {
val timeElapsed = (coffee.time.toScondOfDay().toDouble() - st.toSecondOfDay().toDouble())/3600
coffee.concentration = sc*exp(k*timeElapsed)
}
return data_list
}
fun main() {
val start_time = LocalTime.of(8,0)
val time2 = LocalTime.of(23, 0)
val second_start = LocalTime.of(12,0)
val start_conc: Double = 150.0
val second_dose: Double = 150.0
val half_life: Double = 5.0
val k: Double = ln(0.5) / half_life
// Get Time schedule and calculate concentrations
var coffee_list = get_dc_times(start_time, time2)
var second_coffee_list = get_dc_times(second_start, time2)
coffee_list = calculate_conc(coffee_list, start_conc, start_time, k)
second_coffee_lst = calculate_conc(second_coffee_list, second_dose, second_start, k)
// Dataframe operations
val df = coffee_list.toDataFrame()
val df_sec = second_coffee_list.toDataFrame()
var joined = df.leftJoin(df_sec) {it[Coffee::time]}
val concentration by column<Double>()
val concentration1 by column<Double>()
joined = joined.rename(concentration1).into("second_conc")
val second_conc by column<Double>()
joined = joined.fillNulls{second_conc}.with{0.0}
joined = joined.add("total"){it[concentration] +it[second_conc]}
// Add time_hours column (hours since midnight)
joined = joined.add("time_hours") {
it[Coffee::time].toSecondOfDay().toDouble() / 3600
}
// Plot
joined.plot {
line {
x("time_hours")
y("total")
color = Color.BLUE
width = 1.0
type = LineType.SOLID
}
layout {
title = "Total Caffeine Concentration Over Time"
xAxisLabel = "Time of Day"
yAxisLabel = "Total Concentration (mg)"
size = 800 to 400
}
}.save("line_plot.png")
joined.writeCSV("results.csv")
}
The above code uses some java interop for the time calculations (which I included before I used Gradle as my build tool). It also takes advantage of the kandy plotting library and kotlin dataframes. Here is the graph output for our model.
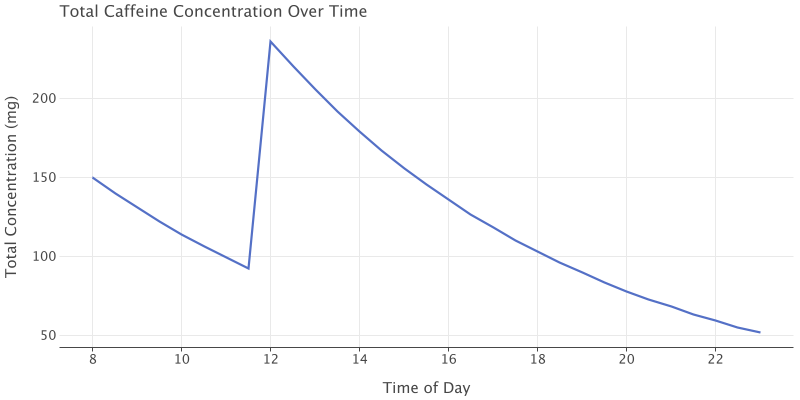
If we have two espressos during the day, which for me is a Nespresso machine using the double espresso scuro pods at 150mg each, we can space out our intake such that we will minimize jitters from spiking too much caffeine at one time and we can avoid the most potent drawback to using caffeine, which is the impact on your sleep. According to research, doses as small as 100mg can disrupt sleep (source), so our goal should be to have our blood concentration fall below that at bedtime with some factor of safety. Looking at our model output, an espresso at 8 am, followed by another at noon ensures that our total concentration is under 100 with some margin by bedtime, in my case usually around 10 pm. This model is a simplification, because it takes time, approximately 30-60 minutes, for the caffeine you intake to reach peak levels in your blood, so treat the dose times as the actual intake time + 30-60 minutes.
What I like
Now before you Kotlin groupies lay into this code, note that it’s my first journey into the language. The fact that I don’t use all of your favorite idioms is ok. I want to learn them though. I want more people in my space (Data Science) to start using it. Is it going to be the best tool for Exploratory Data Analysis? Probably not, however it easily covers that use case with access to Kotlin Notebooks, specifically the Jupyter notebook kernel that allows you to run Kotlin in a more dynamic way. The power of this language is that the static typing and its compiled nature don’t interfere too much with the experimental type mentality of EDA or other data science workflows, given its expressibility and existing ecosystem for data work. Plus you get all of the things you would want from a production ready language. Perhaps it will solve the two language problem? One can hope.
With that in mind, what do I like about Kotlin that is expressed in this code snippet?
- Data Classes - Python has these tacked on but they are built into the language here. The first thing I thought of was that they are similar to ORMs when you want a programmatic interface to SQL schemas. They translate really well to kotlin dataframes as well. I believe under the hood the dataframe library uses extension functions, but again I’m new to this and could be wrong.
- Static typing and inference - requires you to think more about the data flowing through your program, but not to the extent of Rust where you have to perform ownership semantics. A good middle ground.
- Pythonic functions - named arguments with defaults are really nice, along with an explicit return statement.
- Data science ecosystem - notebooks, plotting libraries, REPL, and interop with mature ML libraries. Amazing start!
So there we have it. I dipped my toe into a large, new world. Hopefully I will dip much more in the future, but not like that. A final technical note: this project is built with Gradle, which I won’t go into detail about here. It’s different than making packages in Python, though I found that after a bit of tinkering (while my wife was watching Pride and Prejudice while I also “watched” from behind my computer), I was able to get it to work. I like Kotlin a lot, and I hope to use this incredible language in my professional work going forward.
Here is a fun exercise to do in closing. Take the above code and abstract it out to accept arbitrarily many coffee breaks. I often do two in a normal day, but can you have the code generate more or fewer without manually adding it every time? I imagine a factory like class would be useful. Have fun!
![]()